C言語で自作RISC-Vを動作させる
前回の記事でアセンブラでLチカ、Hello worldはできました。
今回はC言語で試してみました。
実用性を求めるとC記述でも動作することが重要ですが、なによりもハーバードアーキテクチャの場合、Load/Store動作のデバッグになると思います。関数にジャンプする時、main関数にreturnする時、容赦無くLoad/Storeの連発をするからです。
2,3個Load/store命令が連続しているようなコードでは動作(実際はしていないのだけれどもタイミングの功罪で動いているように見える)していても、数十回連続すると動作しない事態が起こり得ます。
Cでは容赦無くLoad/Store行うので、良い試験になります。
GCCの準備
いままでアセンブラのみ使っていたためまともな環境を構築していませんでした。
※ビルドに必要なパッケージ(automake autotools-dev curlなどなど)はすでに導入済みとします。
git clone https://github.com/riscv/riscv-gnu-toolchain cd riscv-gnu-toolchain ./configure --prefix=/opt/riscv --with-arch=rv32i sudo make
ここで、/opt/の権限によりますがsudo makeしないと不可解なエラーになります。permission deniedって出ればわかりやすいのですが。
.bashrcなどでPATHを通したら完成です。
$ riscv32-unknown-elf-gcc -v Using built-in specs. COLLECT_GCC=riscv32-unknown-elf-gcc COLLECT_LTO_WRAPPER=/opt/riscv/libexec/gcc/riscv32-unknown-elf/10.2.0/lto-wrapper Target: riscv32-unknown-elf Configured with: /mnt/c/riscv-gnu-toolchain/riscv-gcc/configure --target=riscv32-unknown-elf --prefix=/opt/riscv --disable-shared --disable-threads --enable-languages=c,c++ --with-system-zlib --enable-tls --with-newlib --with-sysroot=/opt/riscv/riscv32-unknown-elf --with-native-system-header-dir=/include --disable-libmudflap --disable-libssp --disable-libquadmath --disable-libgomp --disable-nls --disable-tm-clone-registry --src=.././riscv-gcc --disable-multilib --with-abi=ilp32 --with-arch=rv32i --with-tune=rocket 'CFLAGS_FOR_TARGET=-Os -mcmodel=medlow' 'CXXFLAGS_FOR_TARGET=-Os -mcmodel=medlow' Thread model: single Supported LTO compression algorithms: zlib gcc version 10.2.0 (GCC)
リンカ・スタートアップの準備
参考サイト。みつきん(id:mickey_happygolucky)さんのブログです。
mickey-happygolucky.hatenablog.com
ほぼそのままですが、.text領域と.bss領域がことなりますので、それを書き換え、stackの最終アドレスが0x7fff(ただし4-byte-alignment)になるようにスタートアップコードをなおしました。良記事でした。ありがとうございます。
linker.ld
OUTPUT_ARCH( "riscv" )
ENTRY(_start)
SECTIONS
{
. = 0x00000000;
.text.init : { *(.text.init) }
.tohost : { *(.tohost) }
.text : { *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
_end = .;
}
---------ここから:2021年1月18日加筆修正---------
スタートアップコードは少し修正しています。今回作成したRV32IはPrivillaged ISAの規格通り、Machine-mode timer(mtime)を64bitで実装しています。
下位32bitをget_timel()、上位32bitをget_timeh()で取得できるようにしました。
utils.S
.section .text.init;
.global _start
_start:
lui sp, 0x08
call main
j .
.global dummy
dummy:
ret
.global put32
put32:
sw x11,(x10)
ret
.global get32
get32:
lw x10,(x10)
ret
.global get_timel
get_timel:
csrr x10, time
ret
.global get_timeh
get_timeh:
csrr x10, timeh
ret
Cを記述する
簡単なLチカコードです。こちらもみつきんさんのコードとあまり変わりませんが、タイマーmtimeを使用しています。
コードを記述する前にKyogenRVの現時点で最新のタグが付されているバージョンをcloneします。
git clone http://github.com/panda5mt/KyogenRV -b 0.2.6 --depth 1 make sdk
make sdkでVerilog生成、テストコードのhexファイル生成、今回のテスト用Cコードコンパイルを一括で行います。
Scala/chisel環境のない方は実行しない方がいいと思います。すでにコンパイル済みのhexファイルが消えるので。
後述しますが、今回のCプロジェクトをコンパイルするだけの場合はmake c_allを実行します。
KyogenRVプロジェクトルート/src/sw/main.cを記述します。
github.com
void put32(unsigned int, unsigned int); unsigned int get32(unsigned int); unsigned int get_timel(void); unsigned int get_timeh(void); void dummy (void); #define GPIO_BASE 0x8000 #define XTAL_FREQ_KHZ 60000 // wait msec counter void wait_ms(unsigned int msec){ volatile unsigned int oldtime; oldtime = get_timel(); while((get_timel()-oldtime) < XTAL_FREQ_KHZ * msec); //1msec } // main function int main(int argc, char *argv[]) { while (1) { wait_ms(500); put32(GPIO_BASE, 0x55); wait_ms(500); put32(GPIO_BASE, 0xAA); } return 0; }
標準IOもなにもインクルードしていない状態です。これで動作します。
プロジェクトのルートに戻り、下記を実行します
make c_all
KyogenRVプロジェクトルート/src/sw/blinker.hexが生成されたhexです。
Quartus Primeで使用するインテルhexを生成する場合は
プロジェクトのルートに戻り、下記を実行します
./mk_intel_hex.py
KyogenRVプロジェクトルート/fpga/chisel_generated/blinker_intel.hexが生成されたインテルhexです。
前回のようにPlatformDesignerでon-chip ramの初期値に設定し、コンパイルすることでFPGA上で動作します。
動作風景
youtu.be
逆アセンブル
make c_reverse
で逆アセンブルできます。
どのようなコードになっているか見ることができます。
セクション .text.init の逆アセンブル: 00000000 <_start>: 0: 00008137 lui sp,0x8 4: 0a8000ef jal ra,ac <main> 8: 0000006f j 8 <_start+0x8> 0000000c <dummy>: c: 00008067 ret 00000010 <put32>: 10: 00b52023 sw a1,0(a0) 14: 00008067 ret 00000018 <get32>: 18: 00052503 lw a0,0(a0) 1c: 00008067 ret 00000020 <get_timel>: 20: c0102573 rdtime a0 24: 00008067 ret 00000028 <get_timeh>: 28: c8102573 rdtimeh a0 2c: 00008067 ret セクション .text の逆アセンブル: 00000030 <wait_ms>: 30: fd010113 addi sp,sp,-48 # 7fd0 <_end+0x7ee0> 34: 02112623 sw ra,44(sp) 38: 02812423 sw s0,40(sp) 3c: 03010413 addi s0,sp,48 40: fca42e23 sw a0,-36(s0) 44: fddff0ef jal ra,20 <get_timel> 48: 00050793 mv a5,a0 4c: fef42623 sw a5,-20(s0) 50: 00000013 nop 54: fcdff0ef jal ra,20 <get_timel> 58: 00050713 mv a4,a0 5c: fec42783 lw a5,-20(s0) 60: 40f706b3 sub a3,a4,a5 64: fdc42703 lw a4,-36(s0) 68: 00070793 mv a5,a4 6c: 00579793 slli a5,a5,0x5 70: 40e787b3 sub a5,a5,a4 74: 00279793 slli a5,a5,0x2 78: 00e787b3 add a5,a5,a4 7c: 00479713 slli a4,a5,0x4 80: 40f70733 sub a4,a4,a5 84: 00571793 slli a5,a4,0x5 88: 00078713 mv a4,a5 8c: 00070793 mv a5,a4 90: fcf6e2e3 bltu a3,a5,54 <wait_ms+0x24> 94: 00000013 nop 98: 00000013 nop 9c: 02c12083 lw ra,44(sp) a0: 02812403 lw s0,40(sp) a4: 03010113 addi sp,sp,48 a8: 00008067 ret 000000ac <main>: ac: fe010113 addi sp,sp,-32 b0: 00112e23 sw ra,28(sp) b4: 00812c23 sw s0,24(sp) b8: 02010413 addi s0,sp,32 bc: fea42623 sw a0,-20(s0) c0: feb42423 sw a1,-24(s0) c4: 1f400513 li a0,500 c8: f69ff0ef jal ra,30 <wait_ms> cc: 05500593 li a1,85 d0: 00008537 lui a0,0x8 d4: f3dff0ef jal ra,10 <put32> d8: 1f400513 li a0,500 dc: f55ff0ef jal ra,30 <wait_ms> e0: 0aa00593 li a1,170 e4: 00008537 lui a0,0x8 e8: f29ff0ef jal ra,10 <put32> ec: fd9ff06f j c4 <main+0x18>
---------ここまで:2021年1月18日加筆修正---------
この分量であれば、アセンブラでも追いかけられるレベルです。
SignalTap片手に波形を追いかけながらCPUデバッグをしました。
問題点:riscv-testsがChiselシミュレーション上で失敗する
今回の修正でchisel-iotester上ではriscv-testsが失敗するようになってしまいました。
もちろんCyclone10LP FPGA上では正しく動作します。
理由(だけ)は簡単です。メモリやメモリマップ上のAvalon-MMスレーブの挙動をChiselで完全にはシミュレートできていないからです。
スレーブデバイスのwaitrequest含めたAvalon-MMの挙動をChiselで完全シミュレートする価値があるかというと、目的と手段の入れ替わりが生じているように思えます。今のところその意義を感じていません。そんなことするのであれば一旦Verilogを生成してQuartusでBFMテストに流すべきと思います。
対処としては、下記のいずれか選択をすると思われます
- riscv-testsのChisel上でのシミュレーションは諦める(エラーのまま放置)。
- シミュレーションはパスできるようにする:AvalonMMに対応したバスブリッジを別ファイルで用意し、シミュレーション時は当該ファイルを除外、HDL生成時は含めて生成する
後者の方がスマートですね。あとはやる気の問題かな。
Intel FPGA Cyclone 10LPで自作RISC-Vを動作させた話
この記事を執筆した段階ではアセンブラのみ動作が確認できていました。その後C言語での動作確認も終えています。詳しくはこちらをご覧ください。
自作RISC-V向けにCライブラリの整備やPlatformDesigner連携をする - lynxeyedの電音鍵盤
この記事はQuartus Primeサイドから見たブログ記事にしたいと思います。
CPUを設計する、というお題は私自身16bit/32bitともにあるので*1、ちょうど良いレベルの難易度だったかなと思います。
奇しくも今年はRISC-Vは10周年だそうで。
riscv.org
ターゲットはintel FPGA Cyclone 10LPです。
github.com
git clone http://github.com/panda5mt/KyogenRV -b 0.2.6 --depth 1
プロジェクトルート/fpga/がQuartus Primeプロジェクトになります。Quartus Prime Lite 20.1.1で動作確認。
前回のブログで紹介したあと、いろいろ反響がありました。(ブログアクセス数も1日で450人とか)
使ってくれた方もいました。
とりあえずCYC1000でKyogenRVうごいた。ピン定義設定して書き込んでも動かないのでなんでだ?と思ったら、メモリ初期化パスが絶対パスで書かれるからプログラムが書き込まれてなかったらしい。 pic.twitter.com/peHXwpJbHA
— Kenta IDA (@ciniml) 2020年12月13日
Avalon-MMつかいの魔術師がいじるとこうなる
ちなみに全部作り直すの面倒だったので、手元にあったNiosIIのプロジェクトにRV32を追加してヘテロマルチコアにしてあります https://t.co/OM8Oba8xaS
— 長船 俊@NicoTECH自造社団 (@s_osafune) 2020年12月13日
CPUは魔改造されてからが本番。
CPU諸元
- ISA
- User-Level ISA Version 2.2
- Privileged ISA Version 1.11 (マシンモード)
- 割り込み
- 外部割り込みのみ
- 実行形式
- キャッシュなし、5段パイプライン(フェッチ/デコード/実行/メモリアクセス/レジスタライトバック)、インオーダ実行方式
- 最高周波数
- 70MHz ~ 100MHz(intelFPGAのグレードによる)
- 開発に使った言語
- Chisel v.3.4
- 占有ロジックエレメント数
- 6000LE ~ 12000LEほど(命令メモリ容量や接続モジュールにより変動します)
RV32IのISAに準拠、マシンモードのみ(=スーパーバイザ非対応)ですが、仕様通りの例外(ecallなど)にも対応しています。
割り込みは外部割り込みのみ暫定対応。(タイマー割り込みはメモリマップドモジュールタイマーを設け、トリガーを外部割り込みへ接続し使うようにしてください)
Platform Designerで接続
昨今ではよほど小さなプロジェクトでない限りintel FPGAで動作する=Avalonバス接続可能を意味するレベルでメジャーになってきたと思います。
以下のいずれかの方法でプログラムメモリを接続します。
- 速度パフォーマンスが少し良い方法
命令バス、データバスは独立なので、命令読み込みウェイトがかかる時間が圧倒的に少ない。
今回作ったRV32Iはキャッシュを持たない設計にしたのでこの接続だと処理速度は向上する。デュアルポートRAMなので使用ロジックが若干増える。

- 消費論理回路が少し減る方法
命令バスが、データバスとシェアする方法。命令読み込みウェイトがたびたびかかる。
データバスがメモリ空間に頻繁にアクセスするプログラムだと、上記の接続方法より処理速度が1/2以下になることもある。でも使用ロジックは上記より少ない。
今回の設計では優先度をデータメモリ > 命令メモリとする。メモリアクセス頻度はその優先度の逆なのでBack Pressureで処理してくれる。
ま、でもそんなに変わんないと思う。組み込みCPUの用途でかんがえると永延とデータメモリにアクセスするのみ or 永延とCPU内部で演算しかしないといった極端な動作はあまり考えられないので。RTOS載せるのであればその段階でパフォーマンスの考慮してもいいかもしれない。
- Avalon-MMになんでこだわるのか
一言で言うならば、ペリフェラルまで作りたくないから。Platform Designerで思いつく限りのマイコンとしてのペリフェラルが用意されている。
そのためこちら側はペリフェラルの詳細ロジックを調べることなく、バス上にペリフェラルを繋げていけば良い。楽。
新たにペリフェラルを作る必要が生じても、規格に則って作れば良い。
CPU(マスタ)とペリフェラル(スレーブ)両方の検証とテストとか、恐ろしくてできない。
確かにRISC-V自作界隈、メモリやUARTやGPIOまで自作しているのが散見されます。
あるいはAXIの独自サブセットをつくってやはりペリフェラルまで自分で用意している。それも非難できない側面もあります。
AXIがあまりFPGAフレンドリな仕様をしていないうえ、Xのツールであるビなんとかが自由度高すぎるために設定が大変。(大変だった。キラキラGUIに騙される。もうやりたくない)
Avalon-MMはFPGAのバスとして(同期回路を接続する前提のバスとして)開発されていて、マスタが複数ある場合のアンチグリッドも自動でしてくれるので楽。AXIで疲弊するなら乗り換えも検討するのもいいと思います。Intelに。Cyclone10LP安いし。インテル入ってるって言えるし (古い
サンプルプログラム
- Lチカ
github.com
Platform Designerで0x8000番地に8bit幅のPIOを設置した場合の前提になります。
約0.5秒間隔(CPUが70MHz動作時)で0x55と0xAAを書き込むものです。LEDが接続されているとBlinkが確認できるはず。
ビルドには以下のコマンドをプロジェクトルートフォルダで実行します。(riscv-toolchainとpython3.7以上が必要です)
./build_asm.py ./mk_intel_hex.py
ビルドするとプロジェクトルートディレクトリ/fpga/chisel_generatedにインテルHex形式でバイナリが生成されるので、Platform DesignerでOn-Chip Memoryの初期値に設定しビルドすると動作します。
動作状況:
youtu.be
github.com
UARTでHello worldするサンプルです。9600baud,8N1で送信します。UARTはPlatform Designerで0x8020番地に設置します。
ビルドには以下のコマンドをプロジェクトルートフォルダで実行します。(riscv-toolchainとpython3.7以上が必要です)
./build_asm.py ./mk_intel_hex.py
ビルドするとプロジェクトルートディレクトリ/fpga/chisel_generatedにインテルHex形式でバイナリが生成されるので、Platform DesignerでOn-Chip Memoryの初期値に設定しビルドすると動作します。
動作風景:Raspberry Pi ZeroをOpenOCDドングルかつUSB-UARTの代用にしています。OpenOCD経由でQuartus Primeで生成させたsvfを書き込み、UARTにcuでコネクトしています。
youtu.be
- 自分で作成したアセンブルファイル
プロジェクトルートディレクトリ/src/sw/に作成した*.sファイルを置きます。命令メモリ開始アドレスは0x0000としてください。
ビルドには以下のコマンドをプロジェクトルートフォルダで実行します。(riscv-toolchainとpython3.7以上が必要です)
./build_asm.py ./mk_intel_hex.py
ビルドするとプロジェクトルートディレクトリ/fpga/chisel_generatedにインテルHex形式でバイナリが生成されるので、Platform DesignerでOn-Chip Memoryの初期値に設定しビルドすると動作するはずです。
Chiselを使ったRISC-Vの勉強(最終話:FPGAへの実装2)
今月中にQuartus Primeユーザー向けにもまとめを書きます。ご期待いただければ。
この記事はChiselサイドから見たブログ記事にしたいと思います。
Alternative HDLとしてそこそこ使えるじゃん!という手応えを感じたのとriscv-testsにFPGA実機上でもパスできるようになったので、ここでお勉強は一旦おしまいにしたいと思います。ここから先は、CPUコアへのデバッグロジックの接続、Cコンパイラ向けリンカスクリプトの記述、とChiselではない話になっていきます。
もちろんこれからChiselはかなりの頻度でネタとして取り上げると思います。(現時点で車載LKAS画像認識エンジンの記述に使っています。)
今回ターゲットはintel FPGA Cyclone 10LPです。
RV32IのISAに準拠、マシンモードのみ(=スーパーバイザ非対応)ですが、仕様通りの例外にも対応しています。
割り込みは外部割り込みのみ対応。(タイマー割り込みはメモリマップドタイマーモジュールを設け、トリガーを外部割り込みへ接続し使うようにしてください)
ふつーの32bit組み込みマイコンです。
github.com
git clone http://github.com/panda5mt/KyogenRV -b 0.2.6 --depth 1
プログラム例
徳ではなくLチカ基板を積むのが組み込みエンジニア道らしいのでBlink LEDしてみます。PIOにLEDを接続するものとして、PIOのアドレスを0x8000番地、8bit幅と想定し記述します。GPIOに約0.5secごとに0x55,0xAAを交互に記述します。動作周波数は70MHzとします。
このCPUはmtimeを64bitで実装しています。今回は下位32bitだけを参照します。mtimeはクロックに同期してカウントアップします。(kyogenrv-root-directory)/src/sw/test.sに以下を記述します。
nop
lui x1, 0x08 # x1 = 0x8000
_loop0:
csrr x2, time # x2 = time (oldtime)
li x3, 0xAA # x3 = 0xAA
sw x3, 0(x1) # dmem[x1] = x3 = 0xAA
_loop1:
csrr x4, time # x4 = time (nowtime)
sub x5, x4, x2 # x5 = x4 - x2
lui x6, 0x2160 # x6 = 0x2160_000
bltu x5, x6, _loop1 # if(x5 < x6) then loop
_loop2:
csrr x2, time # x2 = time (oldtime)
li x3, 0x55 # x3 = 0x55
sw x3, 0(x1) # dmem[x1] = x3 = 0x55
_loop3:
csrr x4, time # x4 = time (nowtime)
sub x5, x4, x2 # x5 = x4 - x2
lui x6, 0x2160 # x6 = 0x2160_000
bltu x5, x6, _loop3 # if(x5 < x6) then loop
jal x0, _loop0
記述したら
make test #ここでアセンブルとシミュレーションが行われる ./mk_intel_hex.py
します。python3.7以上が必要です。(kyogenrv-root-directory)/fpga/chisel_generated/test_intel.hexが生成hexです。
(kyogenrv-root-directory)/fpga/がQuartus Primeのフォルダです。Quartus Prime Lite 20.1.1で動作確認しています。
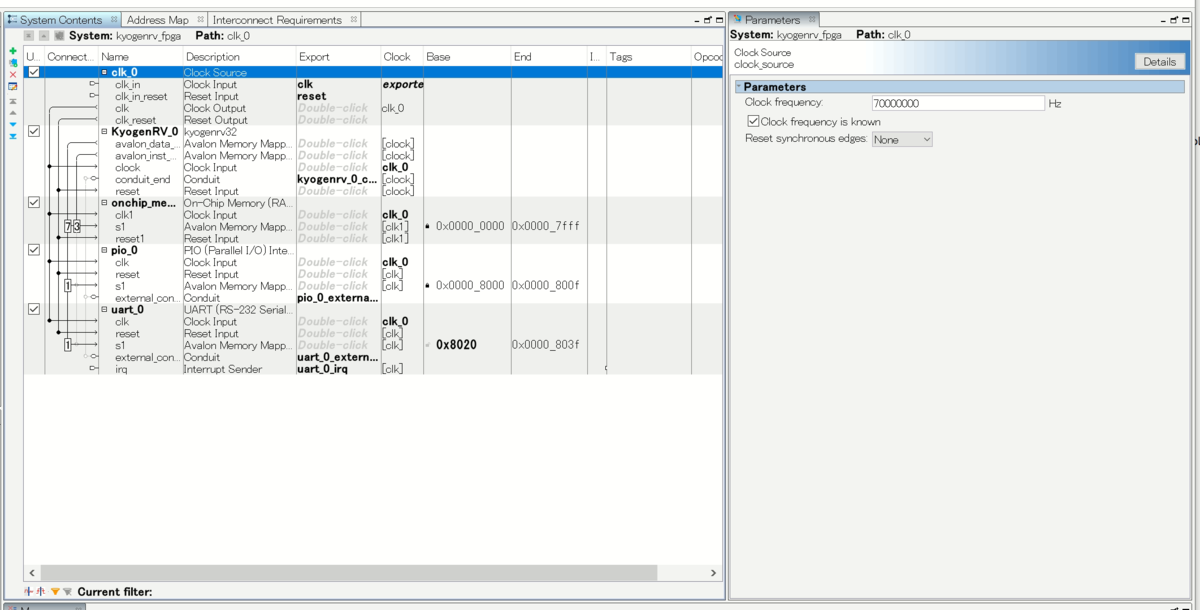
Platform Designer上で、On-chip MemoryのMemory Initializationの項目で先程生成したhexファイルを指定し、Generate HDL-> Finish ->全体のコンパイルをします。
書き込むと、こんな感じ。
youtu.be
以下はこれを設計する際に行ったことと感想です。
Chiselの学習をしてみて
学習コストがすごく高い。座学と簡単な例題解いていても永遠に終わらない気がしたのでRV32Iを設計しながら学習を進めました。
このブログのChisel3のタグで見ていただければ何をやっていたかは把握できると思います。
コストが高いものの、Chisel-iotester*1で実機を使わずとも、バイナリを読み込ませてCPUとして実行した時の挙動が詳細に追えました。
また、Bundleを使うことによって信号線を整理し、再利用がしやすい環境なのも良い点です。メモリ、バス、CPU本体、デバッグ用信号を分けて開発できました。加えて、高位言語ではないため合成された結果がまるで理解不能、ということもありませんでした。(そこまで大した物を作っていない、ということもありますが)
- みんなFPGA使うならメモリはSyncReadMemつかおうね
Chiselそのものが悪いわけではありませんが。同期読み込みではレイテンシが1クロック以上あるはずです。これを前提にしていないRISCV/Chisel教本,ブログがありすぎました。ほんとダメ。ASIC用途ならそれでいいのか知りませんが(多分非同期多すぎてもダメだと思うんだけどどうなのかな)、ASIC起こすユーザそんなにいるのかな。。。非同期メモリはたとえFPGAベンダでサポートしているとしてもロジックの使用率の上昇、Fmaxの低下、期待しないビヘイビアの原因になるので、極力避けたい。
命令メモリ、データメモリ、汎用レジスタを全てMemで記述してる例が多く、ドツボにハマりました。
FPGA実装段階で5段パイプラインを1から作り直しました。
今更なのですが、WBステージで格納した汎用レジスタをEXステージで利用する場合、これが原因で取りこぼしてしまうため、該当する場合のみストールするようにしました。今度一から作り直す機会があったら6段パイプラインにしよう。
- Avalon-MM Master
Avalon-MMスレーブはかなり作っていたのですが、マスタ(しかも命令+データのダブルマスタ)はほぼ初めてでした。かなり難儀しました。
ごくごく普通のパイプラインかつレイテンシが1(Avalon MM自体はレイテンシ変更可能)のメモリとして考えると、ああなんだ、そんなに難しくないじゃん。となります。あと、waitrequestが発生したら問答無用でCPU側(Master側)のステートマシンは全停止させる。ピクリとも動かさない。というのを徹底するとすんなり動きます。
いつもは読めるが、稀に記録もした覚えがない変なデータが読める(1 or 2ビットだけ異なるというのがよくありました)、違うアドレスに書き込んだ値が読める、しかも再現不能という場合はwaitrequestが来ているにもかかわらず、マスタを動かしている可能性があるかもしれません。
さいごに
Cyclone 10LPはイイゾ。
*1:これがなかったらChiselの価値ない気がします。なかったら勉強しませんでした
Chiselを使ったRISC-Vの勉強(14.Intel HEXの生成)
Intel Hexファイルの生成
Intel FPGAで初期値をRAMに与えたい場合、インテルHEXかMIFファイルにしておく必要があります。
https://www.intel.co.jp/content/dam/altera-www/global/ja_JP/pdfs/literature/ug/ug_ram_rom_j.pdf
今後、OpenOCDでデバッグできるIFを実装する予定もありMIFではなくインテルHEXを選択しました。
lynxeyed.hatenablog.com
今までChiselプロジェクトには独自形式のHEXファイルを使用してきました。チェックサムもアドレスもない、0x0000番地から始まることかつ32bit長が前提のものです。文字列処理が煩雑にならないので便利でしたが、ここでインテル形式も生成できるようにしました。
インテルHex形式の規格
Wikipediaにあります。これ以上分かりやすい解説がなかったので。
en.wikipedia.org
今まで生成していたHexファイルにスタートバイト、バイトカウント、アドレス、レコードタイプ、チェックサムを追加するのが楽そうです。
ここはshとかMakefileで書ければ良かったのですが、ちょっとめんどくさかったので、pythonで書きました。10~20分もあればできてしまうような内容です。
僕は半日かかりました。天才なので。
コードの主要な部分です。
アドレスをインクリメントして、16進数で表記、チェックサムを間違えなければ難しいところはありません。
ex_start_code = ':' hex_byte_count = '04' hex_start_addr = 0x0000 hex_record_type = '00' hex_end_of_file = ':00000001FF' line = fr.readline() while line: hexdata = line.strip() li_hexdata = conv_hexlist(split_n(hexdata,2)) # read hexdata -> list li_hexaddr = conv_hexlist(split_n(format(hex_start_addr,'04x'),2)) checksum = (0 - (int(hex_byte_count) + sum(li_hexaddr) + int(hex_record_type) + sum(li_hexdata))) & 0xff wr_hex = hex_start_code+hex_byte_count+format(hex_start_addr,'04x')+hex_record_type+hexdata+format(checksum,'02x')+'\n' fw.write(wr_hex) hex_start_addr = hex_start_addr + 1 #increment address line = fr.readline() fw.write(hex_end_of_file+'\n') fw.close fr.close
適当。
KyogenRVのプロジェクトトップで下記を実行します。
make test #ここで今まで通りのHEXファイル生成 ./mk_intel_hex.py #上記HEXファイルを読み込み、インテルHEXファイルを生成
test_intel.hexというインテルHEX形式ファイルが、fpga/chisel_generated/に生成されます。
コード全文
高度運転支援向け単眼カメラの実装(1.MATLABでパーティクルフィルタを実装し評価してみる)
パーティクルフィルタの詳しい内容は扱いません。OpenCVのチュートリアルなどに詳しく扱われています。
例題として、特定の色のカラーボールの追跡はよく扱われます。
以下の手順をとることが多いでしょう。
- 入力画像をHSV変換→ 一定の輝度を持っているピクセルから色相を取り出し → 特徴点
- パーティクルフィルタをばら撒く
- 各パーティクル上、または一定の距離以内存在する特徴点の数*1 → 尤度の決定
- 尤度の高い座標にカラーボールが存在すると判定
- 4.で得られた座標を考慮しつつ、カラーボールが次の状態でどこに向かうか推定する(リサンプリング)
- 3.へ
今回やってみた内容もそれほど変わりませんが、少し工夫をしています。
特徴点の定義
グリーン背景などで、カラーボールを動かす場合は一定の輝度のときの色相を取り出して判定し、特徴点とすることが多いようです。この場合はこの方法はとても有用です(室内の光が少々変わっても追いかけられる)
しかし、車の場合は様々な色をしており、とりまく環境光は絶えず変化しています。加えて昼夜の違いによる大きな輝度変化などがあります。
MATLABでさまざまな画像を入力して、何をパラメータとするとよいか調べたところ、
輝度勾配と色相勾配の内積
が今のところ有用ではないかとみています。
具体的には画像から5x5ピクセル画像を走査し
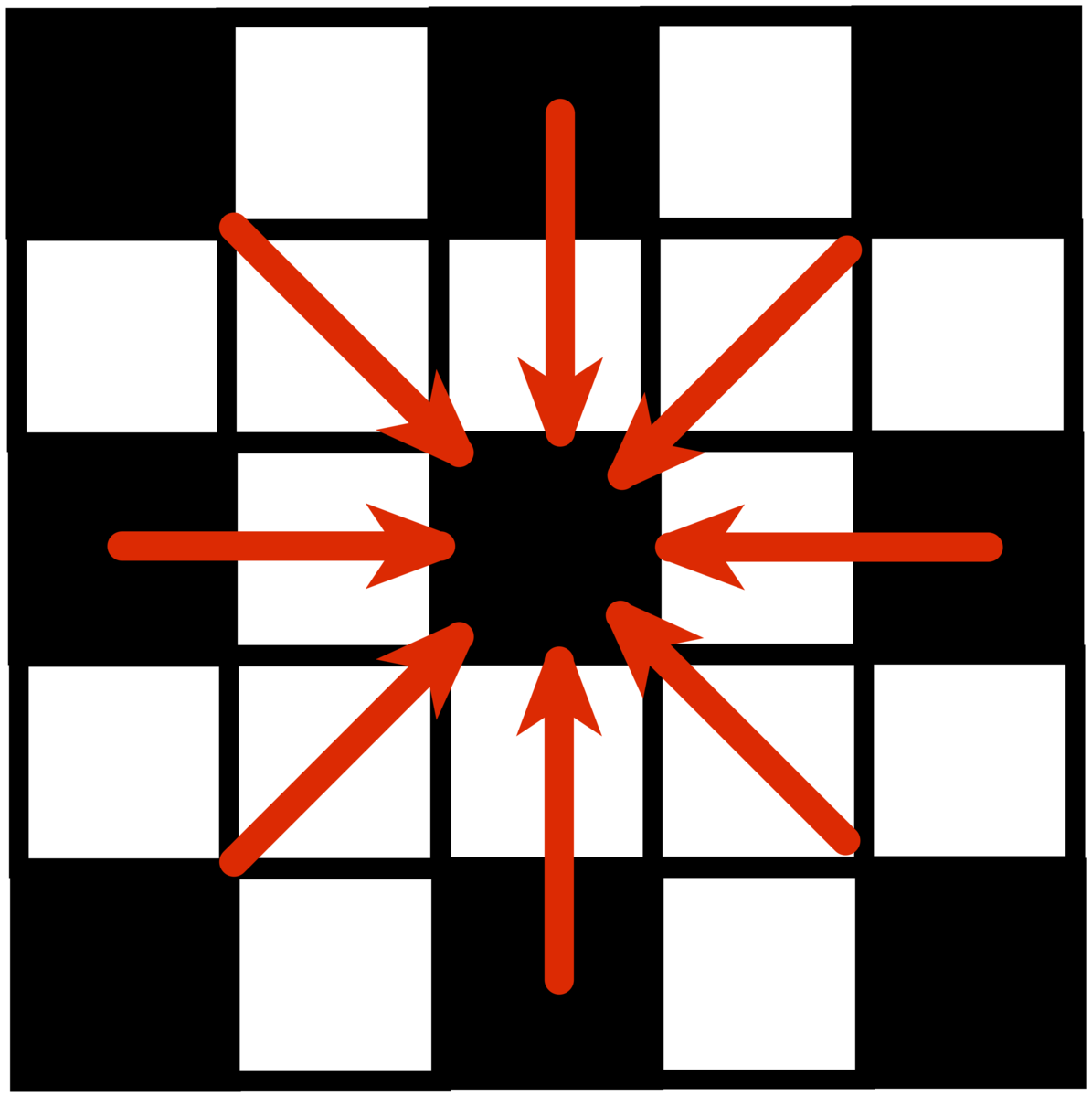
それぞれの内積を考慮すると道路と車の区別がつきやすそう、という判断をしました。
これについてはもう少し調査が必要です。現在試験運用中ですが、かなり課題が見えてきています。追加のパラメータが必要だと思います。
パーティクルフィルタの実装
演算量が少ないのは良い事です。
車のドラレコ映像を例にあげます。

衝突回避の目的であれば、この場合必要なデータは

このように考えれば、入力映像のほぼ上半分は演算から除外することができます。
入力される映像は1000x1000ピクセルを想定しています。
特徴点を5x5で演算するので、パーティクルフィルタの演算に必要な領域は1000/5 x 100/5 = 200 x 200ピクセルです。
パーティクルフィルタの行列を以下のように定めます。
PM(x座標, y座標, 重み)
これが、パーティクル数Pだけ増えます。今回のアプローチではPは200~500くらいが良いかと思われます。あまり多いと演算に時間がかかりすぎます。少なすぎると追跡ができません。
PM(x, y, w, P)
ここではいきなりMATLABコードを出します。
別言語で実装を考えている方にもある程度判断がつくようにコメントしてます。私も最終的にSystemVerilog + C/C++での実装が必要なので。
パーティクルの初期化
% パーテクルフィルタ初期化 % xは1~(200-20)までのレンジ、yは画像下半分(100 ~ 200-20)までのレンジ % 中央の周辺にまずパーティクルを集めてばら撒く function PM = pm_init(PM,P) for m=1:1:P PM(1,1,m) = 100 + randi([-70 70]); PM(1,2,m) = 100 + randi([0 80]); end PM(1,3,P) = 1; end
先ほど述べたように、
パーティクルフィルタの動き回れる領域は200x200です。y座標だけはパーティクル フィルタの動き回れる領域を下半分にしています。(なので実質200x100)
尤度の計算
ランダムにおかれたパーティクルを左上端として、20x20ピクセルを走査し、合計値を格納します。行列Xaは特徴点が格納された200x200の行列です。
% 尤度計算 function PM = likelihood(PM,P,Xa) for m = 1:1:P x = PM(1,1,m); y = PM(1,2,m); A = sum(Xa(y:y+19, x:x+19),'all'); PM(1,3,m) = A; end end
リサンプリング
今回は単純ランダムサンプリングという手法を用います。パーティクルフィルタの重みの累積和を求めて格納し、重みに応じて乱数を生成し、次のサンプリング座標を決定します。重みが小さい=成績の悪いフィルタは、良いものに置き換えられます。
% リサンプリング function [last_w, new_PM] = resample(PM,P) new_PM = zeros(1,4,P); %新しい配列の作成 weights = cumsum(PM(1,3,:)); %重みの累積和 last_w = weights(length(weights)); if last_w == 0 last_w = 1; end for n = 1:1:P w = randi(last_w); for lp = 1:1:length(weights) if w < weights(lp) break; end end %disp(lp); % lp => index new_PM(1,3,n) = PM(1,3,lp); % ウェイトをコピー new_PM(1,1,n) = PM(1,1,lp); % xをコピー new_PM(1,2,n) = PM(1,2,lp); % yをコピー end end
期待値の計算
期待値の座標から推定して黄色い四角を描きます。
元の入力画像に書き戻す関係で、x,y比率を5倍にしています。
function picRGB = pm_draw(PM, P, picRGB) weight = sum(PM(1,3,:)); x = 0; y = 0; for m=1:1:P x = x + (PM(1,1,m) * PM(1,3,m)); y = y + (PM(1,2,m) * PM(1,3,m)); end cX = (x * 5 / weight); cY = (y * 5 / weight); picRGB = insertShape(picRGB,'Rectangle',[cX cY 100 100],'LineWidth',5); %黄色の四角を描画 end
次の状態の予測
トラッキングしたパーティクルフィルタが次にどこへ移動するかを予測します。ここでパーティクルが動ける領域を可変させると、より良い追跡が可能かもしれません。
function PM = pm_predict(PM,P) for m=1:1:P x = PM(1,1,m) + randi([-10 10]); if x < 1 % x座標の稼働領域を指定 x = 1; elseif x > (200-20) x = 200 - 20; end y = PM(1,2,m) + randi([-10 10]); if y < 100 % y座標の稼働領域を指定 y = 100; elseif y > (200-20) y = 200 - 20; end PM(1,1,m) = x; PM(1,2,m) = y; end end
作ってみた
重みの合計値などから、特徴点が異様に少ない時を判別できると思います。この時は全体的に暗めな場合が多いです。
もちろん特徴点が本当にない時と区別をつける必要があります。この辺りは工夫して実装すると面白いと思います。
youtu.be
参考
*1:あくまで例です。なにをもって尤度とするかは実装に依ります
Chiselを使ったRISC-Vの勉強(13.FPGAへの実装1)
メモリを同期読み込み書き込みにする
製作してきたChiselプロジェクトをFPGAに実装してみました。
Chiselを使ったRISC-Vの勉強(1)から目標にしていたようにAvalon-MM Masterとして動作させようとすると、
- 命令フェッチ時にデータ取得が1クロック遅れる
- ロード動作時に1クロック遅れる
(= どちらもメモリ読み込み動作時にのみ1クロック遅れる)
という現象が生じていました。これはChiselで命令メモリ/データメモリをMem(同期書き込み・非同期読み込みメモリ)として実装していたからです。
命令メモリ、データメモリ共にSyncReadMemに置き換えました。
github.com
git clone http://github.com/panda5mt/KyogenRV -b 0.1.1 --depth 1
超ミラクルスーパーウルトラ大規模改修工事の恐れがありましたが、パイプライン動作そのものを大きく変更するような変更がなかったため比較的小規模な改修ですみました。riscv-testsも変わらずパスしています。
この修正に伴い、追加で修正した分
- メモリR/W動作をハンドシェイクからレイテンシ動作に変更
Avalon-MMでは指定されたレイテンシでメモリリードライトを行います。もしスレーブが期待されたレイテンシで応答できない場合、スレーブ側はホストへwaitrequest信号を発行します。
ですので、Chisel側も準じた実装に変更しました。レイテンシに対応したステージでR/W動作を行い、waitrequest信号がきたらストールするだけです。(かえってハンドシェイク方式より単純になりました)
FPGAへの実装テスト
ここでQuartus Primeの使い方を紹介するつもりはないので少し駆け足で説明します。
ハーバードアーキテクチャCPUソフトコアをAvalon-MM Masterとする場合、命令メモリとデータメモリの2つのMasterを持つと思います。
この二つは独立ではなく、Back Pressureに支配されて連携動作をします。(今回はキャッシュ非搭載のため、命令/データは都度フェッチします)
- ChiselプロジェクトからVerilogコードを生成させる。
- PlatformDesignerに読み込ませるためのトッププロジェクトを作り(今回はSystemVerilog)、上記コードをインスタンスする。
- 新規プロジェクトを作り、PDで上記CPU + On-chip Memory + IOを使ったプロジェクトを作る
- hexエディタで命令を書く
- SigmalTapで実行中のCPUの動作を確認
項目2.の信号はavalon-MM Master信号と下記のように対応させました。

- clock
- reset
- byteenable
- waitrequest
- address
- read
- readdata
- write
- writedata
PlatformDesignerに登録が終わったら、項目3に進んでいきます。
それぞれの接続は以下のようになりました。onchip_memoryは0x0000番地から、I/Oはデータメモリ開始番地0x8000に配置します。

項目4.
以下は疑似コードです。これをアセンブラで記述します。今回書くコードの目的は命令/データメモリが正しく動作しているかの確認です。
uint32_t data; *(*PIO_BASE_ADDRESS) = 0xAA; // PIO = 0xAA data = *(*PIO_BASE_ADDRESS); data = data + 1; *(*PIO_BASE_ADDRESS) = data; // PIO = 0xAB
上記をアセンブラで記述します。
lui x1, 0x08 # x1=0x8000 li x2, 0xAA # x2 = 0xAA sw x2, 0(x1) # dmem[0x8000] = 0xAA lw x3, 0(x1) # x3 = dmem[0x8000] addi x3, x3, 1 # x3 = x3 + 1 sw x3, 0(x1) # dmem[0x8000] = x3 _loop: jal x0, _loop # loop
と書いてもいいのですが、これだとデータメモリに格納される前にデータフォワーディングでRWされるデータがよしなに取り扱われてしまうので、適宜パイプライン段数以上のnopを入れてやります。そうすることで本当にデータメモリの読み書きが機能しているかを確認することができます。
lui x1, 0x08 # x1=0x8000 li x2, 0xAA # x2 = 0xAA sw x2, 0(x1) # dmem[0x8000] = 0xAA nop nop nop nop nop lw x3, 0(x1) # x3 = dmem[0x8000] nop nop nop nop nop addi x3, x3, 1 # x3 = x3 + 1 nop nop nop nop nop sw x3, 0(x1) # dmem[0x8000] = x3 _loop: jal x0, _loop # loop
みたいな感じです。アセンブルして、得られた機械語をQuartusのHexエディタで記録保存、Onchip Memoryの初期値データとします。
SignalTapで動作状況を見てみました。

ロード命令も動作しています。waitrequestにより1クロック待たされていますが、動作しています。
Chiselを使ったRISC-Vの勉強(12. riscv-testsの全項目クリア)
riscv-testsクリア
riscv-testsのリグレッションテストを全てクリアしました。(fence.i命令は除外しました。RISC-Vの基本Iアーキテクチャでは必須ではなくなったからです。)

テストがfailしたもののほとんどはCSRに起因し、CSRレジスタのフォワーディングの実装の間違いに起因するものでした。
これはトレース結果を見ればすぐにわかるので修正→全テストのやり直しを繰り返せばクリアできるものが仕上がっていきます。
ここでは覚書としてクリアするのに1日以上かかった項目を挙げていきます。
CSRの実装 ≒ 例外の実装
intel FPGAに実装する際、カスタム命令を実行するコプロセッサを接続する予定なのでCSRを結局外してしまうのですが、ISAに定められている例外を正しく実装する事はコプロセッサを作る際の参考にもなるため、CSRをできる限り正しく実装することには意味があると言えます。
RISC-Vはフラグを持っていないCPUなので例外に頼る必要もあると思われます。
躓いていたテストは以下の実装でした。
- rv32mi-p-illegal
- rv32mi-p-ma_addr
- rv32mi-p-ma_fetch
- rv32mi-p-shamt
- rv32mi-p-illegal
illegalに関しては今回はRV32Iのみのアーキテクチャであり、RVC(圧縮命令)の実装をしていないので、16bit命令が来た際に正しく不正命令例外を発生させればよくクリアできました。
- rv32mi-p-ma_addr
load/storeのミスアラインアドレスのテストです。
ここで例外が発生したときにmepc(発生時のpc)に加えて、mtval(発生する要因となった命令そのもの)を格納する実装をしました。
- rv32mi-p-ma_fetch
CSRモジュールはEXステージの時のPC,ALUへの入力値(rs1,rs2,immなど)を与える実装にしています。ミスアラインが発生するのは分岐命令時です。分岐先に指定されているアドレスが不正なために例外が発生します。
- jal, jalrは条件なく分岐
- branch命令は条件成立で分岐
これが少し厄介な状況を生み出します。jal/jalr命令は分岐先を調べて即例外を発行できるのに対し、branchは少なくともmemステージ(=ALUから比較結果の回答待ち)まで待たないといけません。ですので以下のような対応にしました。
- jal, jalrは不正なアドレスを確認したら即例外発行
- branch命令はpcと命令を一旦仮に格納(mepc,mtval)→分岐後不正なpcであった場合仮格納していたpcと命令を復元し例外発生
としました。ここで、「jal/jalrもいっしょの挙動にすりゃいいじゃん」または「CSR動作中は本体CPUストールすれば?」となります。
後者は検討中です。CSR自体もパイプライン動作をしているので「CSRモジュールが動作中か否か」という条件を洗い出す作業とALUをCSRに引き渡すロジックの追加が必要になります。
前者は容易に思いつきますができません。理由は以下の通りです。
jal rd, <jump_address>
とした場合、rdにはこの命令の次のpcが格納されます。不正なアドレスにジャンプした後に例外判定をすると、rdが更新された後になってしまうため、rdの値をこの命令実行前の状態に復元する必要があります。
できなくはないけどする必要は全くないですし、いらない32bitのレジスタと配線を増やしてFPGAの動作を低下させる必要はないですね。
この命令もそうですが、パイプラインのなるべく早い段階で例外を発見し処理すると不要なパイプラインレジスタを実装せずにすみ、論理回路消費を抑え、高速化に寄与します。
- rv32mi-p-shamt
シフト命令で(※純粋なシフト命令のみのテストではない)テストパスできないなんてあるのか楽勝じゃん?とおもったら最後までPassできずに泣いていました。
躓いていたのはこの命令。
slli a0,a0,0x20 // a0 = a0 << 32
32bitシフトしたらゼロにすりゃいいのでは?と思っていたら、そういう理由ではありませんでした。
RV32Iでこの命令の即値は5bitです。つまり、0x20という表現はできません。不正命令として例外吐く動作が正しい挙動でした。基本的すぎるミスでウケる。
と、こんな感じでようやくクリアできました。
ここまで到達するのに3ヶ月。長かったですね。
今後
ランダムテストを通しながら以下の独立した試行をやっていきます。
コード
ここまでのコード全文は以下で。
github.com
コードは今後も漸進的に更新されるので、以下のように-bでタグを指定してcloneするのがいいと思います。
git clone http://github.com/panda5mt/KyogenRV -b 0.1.0 --depth 1