RA8E1基板を作る(その4:レーダーとの接続)
そろそろ次のお題に行こうかというところで,基板を使ってもらってる某所から依頼がありました.
「FMCWかパルスかどちらでもいいけどレーダーを動かせないか.軽量なAIで」
昨今車載ではADASや『ドアパンチ』防止センサー,乳児置き去り防止センサーとしても注目されてるものですが,突き詰めて行くとAIを避けて通るのが難しいエッジデバイスですね,レーダーって.ゴーストだったり,あえて無視したい位相信号とかをどうすべきかって.
いろいろなアプローチ見てきたけど,AIというほどでなくても線形な信号処理だと早めに限界が来たりします.
もちろんFFTのみでかなりの情報を取り出せるので,組み込みフレンドリなセンサーではあります.

仕様を検討中のレーダーですが,勝手なイメージでArduCamでいうところのDVPみたいなインターフェースなのかなと思っていたのですが実際はQSPIでした.
RA8E1で扱うのがやっかいな奴です.
RA8のQSPIはR_OSPI_Bベースになっていますが,OctalRAMがすでにこのR_OSPI_Bを使用しているためQSPIを使う際には一部バスを共有することになるからです.
CS信号で切り替えができますが,レーダーとOctalRAMはそれぞれの動作可能周波数と使用するビット数が異なります.いまOSPIに接続しているOctalRAMがレーダーの読込速度に律速されるか,最悪全く使えなくなる可能性があります.信号品質は間違いなく悪化するのでそれに耐えられるかも見積もる必要があります.
いままでスタブもなくL1のみで信号を配線していました.しかし今回の改変でCLK/D0/D1/D2/D3はすくなくともスタブが必要になります.またL4から配線を引き出すとなると基準面のGND(L2)から遠ざかってしまいます.L3は電源層です.信号劣化は避けられません.
最悪な改変となってしまいそうですが,やってみましょう.
TIの資料を読んで見ました.
https://www.ti.com/lit/an/slla414a/slla414a.pdf
交流的に考えると系に戻ってくる電流が遠回りをするため,ジッタ増加,振幅低下,干渉,遅延増加につながります.
今回は"帰り電流"が1.8V電源プレーンに戻れるようにしてやればいいわけです.
3 General High-Speed Signal Routingを見ると,reference plane change が避けられないとき,1 µF以下の stitching capacitor を plane crossing のできるだけ近くに置くよう勧めています.これに従い,スタブ周辺に0.1uFのstitching capacitorを配置しました.またレーダーに分岐するseries resistorとして22ohmを追加しています.よってレーダーのQSPI信号はドライバ近傍に設置している33ohmもあるため,合計60ohm弱の重めの抵抗が加わります.
レーダーの周波数はOctalRAMより遅くし,レーダーからのノイズ戻りを最小限にする,妥協と対策の所産です.

さて,どうなることやら.
ハード的な問題をクリアしても,ソフト的な問題が残っています.レーダーとRAMは同時には動けない訳です.またD-cacheの問題がここで火を噴かないといいなと思っています.最悪RAMは止めてしまい,,レーダー側にある百数十キロバイトのRAMとRA8E1上のRAMで収まるような信号処理にしなければならないかも.
MATLABとRA8E1でHLACを実装する
前回までの一連の作業でOctalRAMを一応メモリマップドに読み書きできるようになったので,次に進みたいと思います.
一応というのはRA8E1がキャッシュ周りの問題を抱えているようで,D-Cacheをオフにしても一定の確率でRWに失敗する問題があり根本解決に至っておりません.
自分の環境に限って言うと,CRC+Write-Modify機構を入れるとこの問題を一応回避できます.もちろん大幅なタイムロスがあります.
早く根本解決しないかな
HLACの実装
組み込みAIフレンドリなCPUですので,軽量な認識ロジックでまず遊んでみようというわけです.
組み込み用途で言うのであればこれまでも「組み込みマイコンでも動く」というものはあったし実際動いていました.
今回採用したRA8E1は最高速度は昨今のハイエンドマイコンでは地味な部類でシングルコアのCPUですが,Cortex-M85のMVE命令は条件付きでベクトル計算できるSIMDの亜種のような構成になっていて,画像のフィルタ演算(たたみ込みを含む)とかFFTなどに威力を発揮します.画像(センサーデータ)取得から前処理,本処理,後処理まで一貫した動作を組み込みマイコン1個でできるのはアドバンテージといえます.あとこのスペックでQFPパッケージってあまりない.
www.arm.com
今回は下記コードをMVE命令を使用し実装しています
- Sobelフィルタ演算
- HLACの25種フィルタたたみ込み演算
- LDAの線形ベクトル演算による分類計算
HLACについては下記ブログが最もわかりやすいです.
techblog.adacotech.co.jp
HLAC
HLACは位置不変性があるため位置変化による学習は逐一しなくても良いことが分かります.
しかし縮尺変化や回転にはそのままではロバストではありません・・・というとネガティブに聞こえますが,回転や縮尺にまで寛容なロジックは個人的にあまり好きではありません.
ルールベースで動くロボットシステムなどでは認識すべきオブジェクトが回転している場合は異常を告げてほしいし,認識してほしいサインが小さいか大きい場合はロボットがしかるべき位置まで前後すべき場合が多いです.というわけで自分のフィールドではHLACほどよい特徴抽出アルゴリズムはありません.
とは言うものの少しの回転や縮尺変化は許容してほしい場合が多いので,まとめてLDA(線形判別分析)で分類してもらいます.
コサイン類似度でも二分木でもいいんですけど,今回はLDAを採用しました.HLACの高速性を無駄にしない方法と思っています.
LDA
HLACの25次元特徴ベクトル に対して,各クラス
のスコアを
のように線形関数で計算し,最大スコアのクラスを選びます.
分類は最終工程の地味な作業ですが,そのくせに結構重い演算を強いられます.でもこのマイコンではさほど苦になりません.
MATLABでモデルを作っておく
実行MATLABコード:hlac_image_capture.m
教師ラベル付与
学習
基本的流れは下記です.
- RA8E1側
- カメラ(OV5642)→ RA8E1 → Sobelフィルタ → UDP(8bit frame) → PC(MATLAB)へ
- MATLAB側
- 画像取得 → ユーザによる教師ラベル付与 → HLAC(order=2, 25次元) → LDA(W,b) → モデル生成
推論
基本的流れは下記です.
- RA8E1側
- カメラ(OV5642)→ RA8E1 → Sobelフィルタ → MATLABが生成した(W,b)からLDA分類 → 推論ラベル出力
学習モデルはと
だけです.
hlac_image_capture.m
で学習用データを収集します.
このMATLABコードはRA8E1基板に接続したカメラからUDP/9000番ポートに流れてくる画像ビューワー兼教師データのラベリング用関数です.入力画像に対してキーボードの入力でラベルを付与します.入力がない場合は入力画像は捨てられます.キーボードの0~9までの最大10クラスです
このときRA8E1基板はただの独自規格・低画素UDPカメラとして振る舞ってもらいます.LANケーブルが必要です.
PCのカメラや写真を取り込む様にしても良かったのですが,最終的にマイコン単独で動く必要があるため,環境の差異を極力避けるためにこうしています.
HLAC推論とLDA分類
学習モデルを作ってくれます.CコードとMATLAB用両方のモデルを生成できます.
実行MATLABコード:hlac_lda_workflow.m
LDA分類についてかるく追記します.
分散が最大となる主成分を計算(PC1)し,そのベクトルと直交するベクトルをPC2とします.分散に貢献するフィルター=支配的なフィルタが判明すればそれ以外の(=分散に貢献しない)フィルタ削減ができ,高速化および省メモリ化に貢献できます.
それぞれの入力のPC1,PC2を分散プロットしたものが下記です.断言できませんが,このプロットの目視でも分離可能かある程度推測できます.

LDA推論も行い精度を出せます

小難しい話も入りましたが,W,bが求められた言うことです.このMATLABコードはヘッダ,および配列としてCコードで生成します.
hlac_lda_model.c
lda_params.h
lda_model.mat ← これはMATLABで推論したいときのデバッグ用です
推論
(オプション) MATLABコード:hlac_lda_workflow.m
スタンドアロンで動くのでMATLABコードは必須ではありません.マイコン側の実行方法は下記
RA8E1のsrcフォルダに上記のコードをコピペしコンパイルします.あるいは下記スクリプト実行でもOKです.
# wsl /linux ./update_c_hlac_model.sh # powershell ./update_c_hlac_model.ps1
RA8E1はカメラ入力に応じて
pred=0 pred=1 pred=1 pred=2 ....
とUART越しに推論結果を出力します.今回はHLACでグーチョキパーを認識させました.
ちょっと学習が足りてない感は否めませんがそれなりに認識してますね.
下記動画はMATLAB側の推論ですが,マイコン側も全く同じモデルで動いているので,同じ推論結果を出力します.
RA8基板でOctal RAMと通信する(Rawデータの送受信)
前回、基板を修正し、無事実装済み基板が到着しました。

RA8E1はSDRAMバスがないもののOSPIメモリを接続することができます。
FSP/RASCを使えば何も考えなくても一発動作...はなかなか難しいので地道にやっていきます。
(注) この記事を記述している時点で未知な部分が大いにあります。ご了承ください。
業務でHyperRAMを使用する際はこんなブログ読んでる暇あるならRAMベンダーとルネサスの両社のFAEからサポートをもらった方が良いと思います。
とりあえず、今回はHyperRAMがマイコンと正しく結線されているか確認します。
下記の動作をクリアできれば少なくとも配線は間違っていないといえます。
方法は
- 電源投入後からレジスタの固定値を読む(ベンダーIDなど)
- ステータスなど値が変化するレジスタを読み書きして、期待した値や挙動になったか確認する
- メモリー空間のどこかに数バイトデータを書き、読み出せるか試す
- 電源断 → 電源再投入して再現するか確認(電源断せずに続行すると前回の結果がRAMに残っているだけの場合がある)
主な特徴(括弧内はメリット)
- 512Mbit(大容量)
- xSPI octal Interface(xSPI Profile2.0準拠。Renesas RASC/FSPでの扱いがxSPI Profile2.0 Extended(いわゆるHyperBUS)に比べて楽)
- 固定レイテンシ(設定が楽:デフォルト設定ならばLC x 2=14固定)
- HYPERRAM 2.0(1.0より新しい。しらんけど)
デメリット
- レイテンシが長い
- 値段がちょっと高い
- 2025年7月1日現在、対応リストには存在していないHyperRAMなので全部自己責任*1
動作確認
まずデータシートから各コマンドを確認し、コマンドを投げて期待する結果がHyperRAMから来るか確認します。ここではospi_raw_transでHyperRAMとデータ送受信をしますが、実態はR_OSPI_B_DirectTransferのラッパーとして振る舞っているだけです。
#define HYPERRAM_BASE_ADDR ((void *)0x90000000U) /* Device on CS1 */ // COMMAND SET(infineon S80KS5123) // #define <COMMAND> <CODE> <CA-DATA> | <ADDRESS(bytes)> | <Latency cycles> | <Data (bytes)> #define OSPI_B_COMMAND_RESET_ENABLE (0x6666) // 8-0-0 | 0 | 0 | 0 #define OSPI_B_COMMAND_RESET (0x9999) // 8-0-0 | 0 | 0 | 0 #define OSPI_B_COMMAND_READ_ID (0x9F9F) // 8-8-8 | 0x00(4bytes) | 3-7 | (4bytes) #define OSPI_B_COMMAND_POWER_DOWN (0xB9B9) // 8-0-0 | 0 | 0 | 0 #define OSPI_B_COMMAND_READ (0xEEEE) // 8-8-8 | (4bytes) | 3-7 | 1 to \infty #define OSPI_B_COMMAND_WRITE (0xDEDE) // 8-8-8 | (4bytes) | 3-7 | 1 to \infty #define OSPI_B_COMMAND_WRITE_ENABLE (0x0606) // 8-0-0 | 0 | 0 | 0 #define OSPI_B_COMMAND_WRITE_DISABLE (0x0404) // 8-0-0 | 0 | 0 | 0 #define OSPI_B_COMMAND_READ_REGISTER (0x6565) // 8-8-8 | (4bytes) | 3-7 | (2bytes) #define OSPI_B_COMMAND_WRITE_REGISTER (0x7171) // 8-8-8 | (4bytes) | 0 | (2bytes) fsp_err_t ospi_raw_trans(spi_flash_direct_transfer_t *p_trans, uint32_t command, uint8_t cmd_len, uint32_t address, uint8_t addr_len, uint32_t data, uint8_t data_len, uint8_t dummy_cycle, spi_flash_direct_transfer_dir_t dir) { fsp_err_t err = FSP_SUCCESS; // Example raw transfer p_trans->command = command; p_trans->command_length = cmd_len; p_trans->address = address; p_trans->address_length = addr_len; p_trans->data_length = data_len; p_trans->data = data; p_trans->dummy_cycles = dummy_cycle; // The configurable latency cycle should be set as minus 1 when Profile 2.0 err = R_OSPI_B_DirectTransfer(&g_ospi0_ctrl, p_trans, dir); return err; }
固定値をリードする
HyperRAM S80KS5123のID0とID1は固定値になっています。(データシートの6.2 Device identification registersを参照)
ID0の下位4bitは製造メーカ0x06(= infineon)固定となっています。Die0をリードすれば0x0F96が読めます。
またID1はデバイスタイプで0x01 (= HYPERRAM 2.0)固定です。
読んでみましょう。Read Registerコマンド(0x65)でリードしてもいいですが、ここはRead IDコマンド(0x9F)でID0,1を同時に取得してみます。
// read ID0/ID1 err = ospi_raw_trans(&g_ospi0_trans, OSPI_B_COMMAND_READ_ID, 2, 0x00000000, 4, 0, 4, 15, SPI_FLASH_DIRECT_TRANSFER_DIR_READ); if (FSP_SUCCESS != err) { xprintf("[OSPI] direct transfer error!\n"); return; } xprintf("ID0/ID1=0x%08x\n", g_ospi0_trans.data);
結果
下記のようになります。
ID0/ID1=0x0100960f
メモリ空間も読み書きする
メモリ空間をライトする場合はWrite Enableコマンドを最初に発行します。またレジスタをライトする場合は都度Write Enableを発行することになります。
// write enable
err = ospi_raw_trans(&g_ospi0_trans,
OSPI_B_COMMAND_WRITE_ENABLE, 2,
0x00000000, 0,
0, 0,
0, SPI_FLASH_DIRECT_TRANSFER_DIR_WRITE);
if (FSP_SUCCESS != err)
{
xprintf("[OSPI] direct transfer error!\n");
return;
}
// write memory
err = ospi_raw_trans(&g_ospi0_trans,
OSPI_B_COMMAND_WRITE, 2,
0x00000080, 4,
0xDEADBEEF, 4,
15, SPI_FLASH_DIRECT_TRANSFER_DIR_WRITE);
if (FSP_SUCCESS != err)
{
xprintf("[OSPI] direct transfer error!\n");
return;
}
// read CR0
// 余計なコマンドを途中に挿入して、「ライト内容が送受信バッファに残っていて、記録できていないのに偶々リードだけうまくいってしまったバグ」の回避
err = ospi_raw_trans(&g_ospi0_trans,
OSPI_B_COMMAND_READ_REGISTER, 2,
0x00000004, 4,
0x00, 2,
15, SPI_FLASH_DIRECT_TRANSFER_DIR_READ);
if (FSP_SUCCESS != err)
{
xprintf("[OSPI] direct transfer error!\n");
return;
}
xprintf("CR0=0x%04x\n", g_ospi0_trans.data);
// read memory
err = ospi_raw_trans(&g_ospi0_trans,
OSPI_B_COMMAND_READ, 2,
0x00000080, 4,
0x00, 4,
15, SPI_FLASH_DIRECT_TRANSFER_DIR_READ);
if (FSP_SUCCESS != err)
{
xprintf("[OSPI] direct transfer error!\n");
return;
}
xprintf("Data=0x%08x\n", g_ospi0_trans.data);
結果
CR0=0x2f8f <- ダミー読み出し Data=0xdeadbeef <- 欲しいデータ
今回使用したプロジェクト
git clone http://github.com/panda5mt/RA8E1_prj -b HYPERRAM_TRIAL2 --depth 1
次回
後編ではRA8E1メモリマップ空間にHyperRAMメモリを展開します。また今回実装していない、AutoCalibrateも実装予定です。
あとがき
HYPERRAMといわれているもの、種類が多すぎて*2この先どこまで生き残るのか、この先もデファクトになるのか謎な感じもします。カオスになってる。またFSPもVer.6.0.0以降OSPIデバイスのバリエーション増やしすぎた様で、対応が追いついていないように見受けられる。JEDEC JESD251/252に対応している=100%動くと言い切れない難しさがあるようだ
*1:S27KL0641はNRNDデバイスなんですけど....

RA8E1をEthernetにつなげる(その2:UDP通信)
前回、LAN8720A PHYの物理的接続とEthernetフレームの送受信を確認しました。
今回はLwIPで高レイヤーの通信を行ないたいと思います。
LwIPを使う際のFSP設定
といってもRASC(FSP)ですでにLwIPはポートされており、必要なものをメニューで選択してほぼ終わりです。
こんな記事書かなくて(見なくて)いいよね、と思うくらいには楽に作成できます。
下記のような構成を取ると思います。
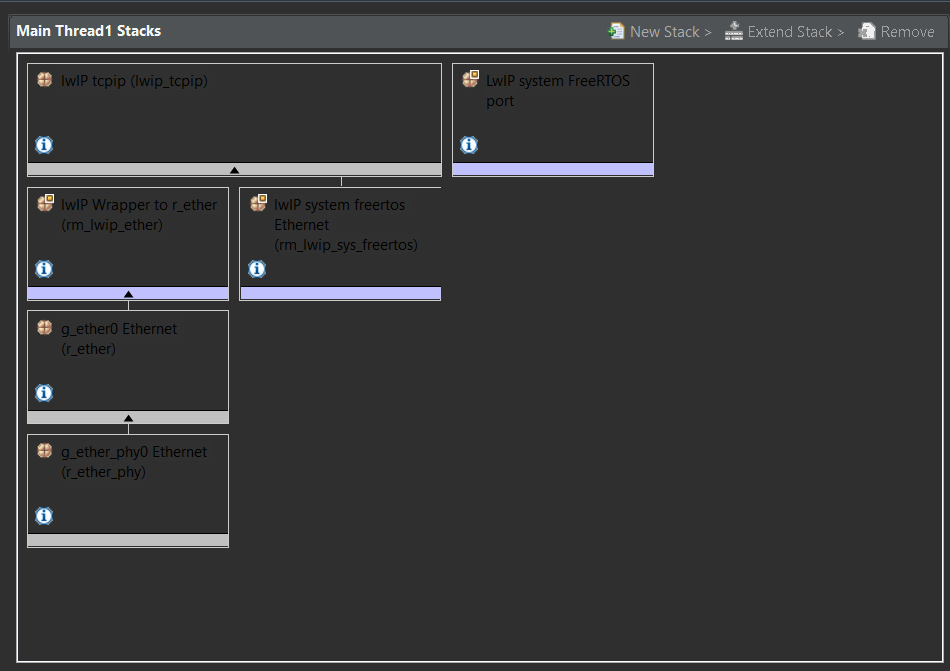
気をつけるべき事は出てきたエラーを消す設定をすること、動作させるFreeRTOSスレッドの後方互換性をEnableにしておくことくらいでしょうか。
- 動作予定のFreeRTOSスレッド内にて
Enable Backward Compatibility=Enabled
g_ether0の割り込み要因EESRの下記イベントをONにするRFOF,RDE,FR,TC
その他必要な設定もする
ソースコード
UDPペイロードを用意し、ポート9000番でブロードキャスト送信します。
DHCPサーバに接続されている前提ですが、PC-基板間のクロス接続であったり、DHCPが存在していないor動かしてはいけない場合があるのでAutoIPも動かしています。DHCP待機タイムアウトは20秒です。
#include "lwip/init.h" #include "lwip/netif.h" #include "lwip/timeouts.h" #include "lwip/udp.h" #include "lwip/dhcp.h" #include "lwip/autoip.h" #define UDP_PORT_DEST 9000 void main_thread1_entry(void *pvParameters) { FSP_PARAMETER_NOT_USED(pvParameters); // LAN8720A Reset R_BSP_PinAccessEnable(); R_BSP_PinWrite(LAN8720_nRST, BSP_IO_LEVEL_LOW); vTaskDelay(pdMS_TO_TICKS(300)); R_BSP_PinWrite(LAN8720_nRST, BSP_IO_LEVEL_HIGH); vTaskDelay(pdMS_TO_TICKS(300)); xprintf("[ETH] LAN8720A Ready\n"); struct netif netif; ip_addr_t ipaddr; ip_addr_t netmask; ip_addr_t gw; IP_ADDR4(&ipaddr, 0, 0, 0, 0); // IPADDR_ANY IP_ADDR4(&netmask, 0, 0, 0, 0); // IPADDR_ANY IP_ADDR4(&gw, 0, 0, 0, 0); // IPADDR_ANY lwip_init(); netif_add(&netif, &ipaddr, &netmask, &gw, &g_lwip_ether0_instance, rm_lwip_ether_init, netif_input); netif_set_default(&netif); netif_set_up(&netif); netif_set_link_up(&netif); dhcp_start(&netif); // DHCP待機 for (int i = 0; i < 2000; i++) { sys_check_timeouts(); if (netif.ip_addr.addr != 0) { xprintf("[LwIP] DHCP assigned IP: %s\n", ip4addr_ntoa(&netif.ip_addr)); break; } vTaskDelay(pdMS_TO_TICKS(10)); } // while (netif.ip_addr.addr == 0) // ; // xprintf("[LwIP] DHCP assigned IP1: %s\n", ip4addr_ntoa(&netif.ip_addr)); // if DHCP is not valid, AUTOIP will Start if (netif.ip_addr.addr == 0) { xprintf("[LwIP] DHCP failed. Using AutoIP.\n"); autoip_start(&netif); while (netif.ip_addr.addr == 0) { sys_check_timeouts(); vTaskDelay(pdMS_TO_TICKS(100)); } xprintf("[LwIP] AutoIP assigned IP: %s\n", ip4addr_ntoa(&netif.ip_addr)); } // UDP通信準備 const char *message = "Hello from RA8E1 UDP"; struct udp_pcb *pcb = udp_new(); if (!pcb) { xprintf("[UDP] udp_new failed\n"); return; } ip_addr_t broadcast_ip; broadcast_ip.addr = (netif.ip_addr.addr & netif.netmask.addr) | ~netif.netmask.addr; for (int i = 0; i < 100; i++) { struct pbuf *p = pbuf_alloc(PBUF_TRANSPORT, strlen(message), PBUF_RAM); if (!p) { xprintf("[UDP] pbuf_alloc failed\n"); break; } memcpy(p->payload, message, strlen(message)); err_t err = udp_sendto(pcb, p, &broadcast_ip, UDP_PORT_DEST); if (err == ERR_OK) { xprintf("[UDP] #%d sent OK\n", i + 1); } else { xprintf("[UDP] #%d send failed: %d\n", i + 1, err); } pbuf_free(p); vTaskDelay(pdMS_TO_TICKS(20)); } udp_remove(pcb); while (1) { vTaskDelay(pdMS_TO_TICKS(1000)); } }
Wiresharkで確認
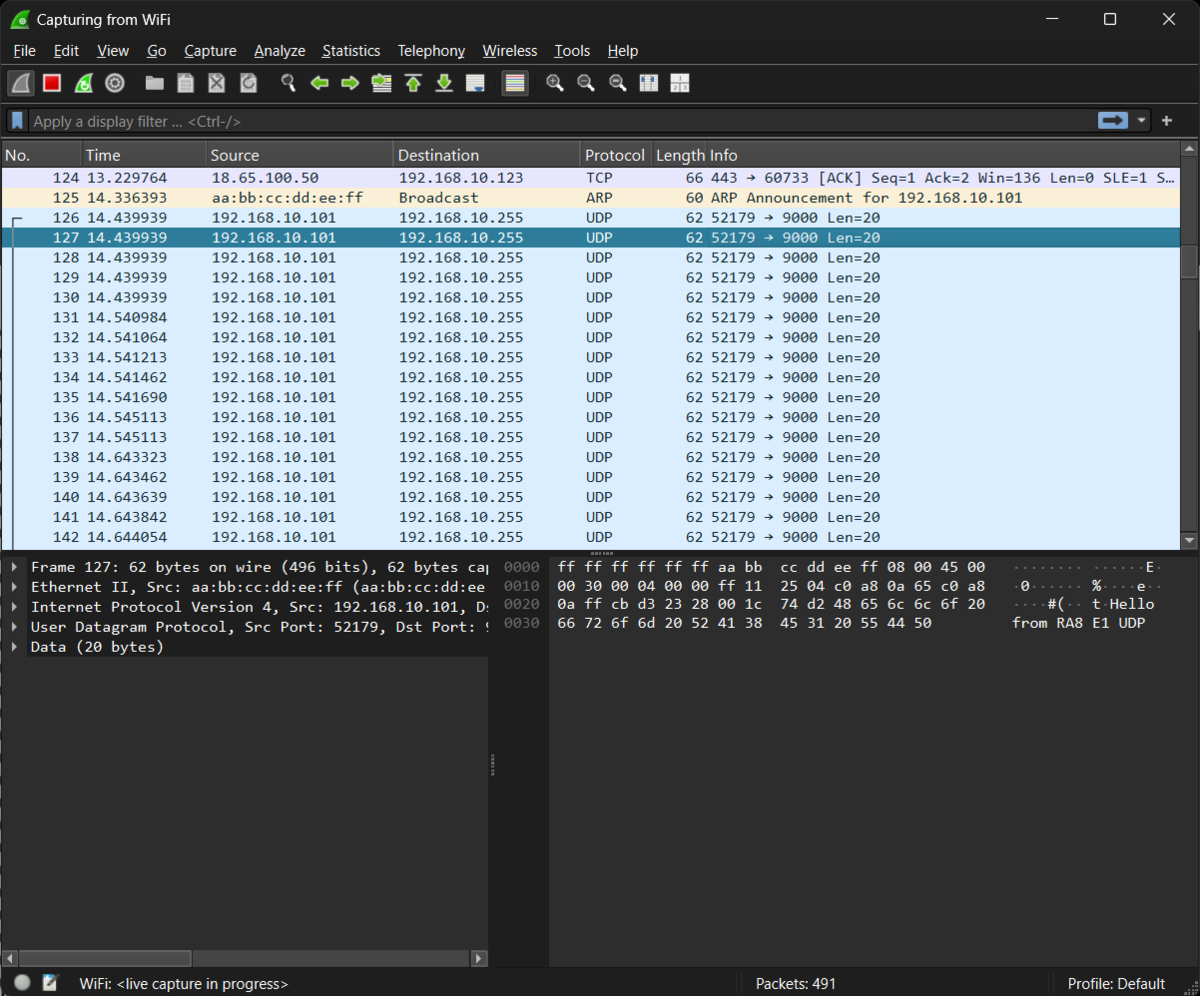
ちゃんとIPを取得できているようです。コンソールからも確認しました。
START [ETH] LAN8720A Ready [LwIP] DHCP assigned IP: 192.168.10.101 [UDP] #1 sent OK [UDP] #2 sent OK [UDP] #3 sent OK [UDP] #4 sent OK [UDP] #5 sent OK [UDP] #6 sent OK [UDP] #7 sent OK [UDP] #8 sent OK ......
タイムアウトはそれぞれの環境で設定すればいいのではないかと思います。タイムアウト後はリンクローカルアドレスが割り振られます。
これから
あとは本丸、hyperRAMをしばくのみ.....
RA8E1をEthernetにつなげる(その1:PHY LAN8720Aの疎通確認)
前回USB-CDCからprintfができるようになりました。
デバッグできる環境が整ってきたのでEthernet PHYも使えるようにしていきます。

長い記事になってしまったので30秒で読める要約をここに書きます
- LAN8720A使った
- PHYからリファレンスクロック50MHz(REF50CLK)が出力されるならRASC(FSP)の設定は
Reference clock=Disabled - イーサーネット送信フレーム長が極端に短い場合、実際には完了しているのに送信完了割り込みが発生しないことがある
おわり。
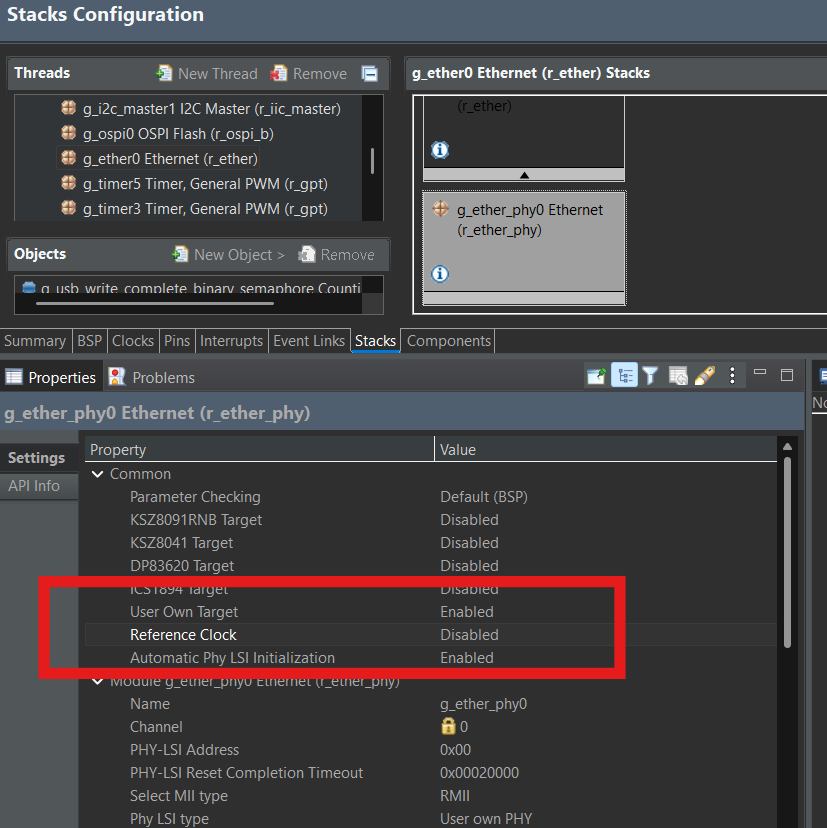
PHYの接続確認
今回はPHYにLAN8720Aを使用しています。
- メリット
- 安価でピン数が少ない
- RMII専用なので切り替え設定が不要
- ピンのプルアップダウンで設定が完了(初期化コマンドいらない)
- リセット後即動作できる
- クロック源の選択(25MHzクリスタル or 50MHz発振器)ができる
- デメリット
- リセットをちゃんとしないと動作しない事がある(データシート参照)
- MIIとの切り替えはできない
- 複数個(3個以上)の使用にはあまり向いてない
- クロック源の選択が面倒
今回の用途には最適です。デメリットは今回ほぼありません。MII要らないし、複数個使わないし。
ハードウェアの留意点
ソフトでの初期化は要りません。その代わり、ハードウェアのピンストラップを正しく行なう必要があります。*1
なお、今回のLAN8720Aのピン設定は下記です。よくあるLAN8720A中華PHYボードとは若干設定や配線が違うのでご注意ください。
MODE[2:0] = b'111です。10BASE-T/100BASE-TX,全二重通信,オートネゴシエーション対応です。
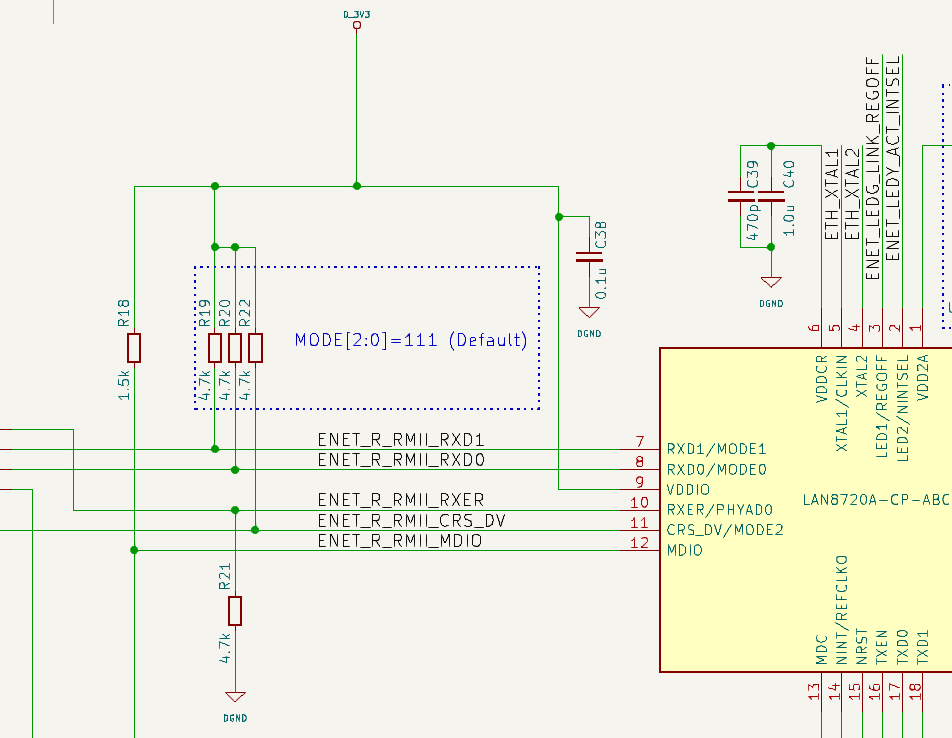
また、PHYAD0をプルダウンしているのでPHY-LSI Address = 0x00となります。
また下記の配線により内蔵1.2VレギュレータON,25MHzクリスタルモード(リファレンスクロックピン:REFCLKO=50MHz出力モード)になります。
ここが唯一めんどくさいところ
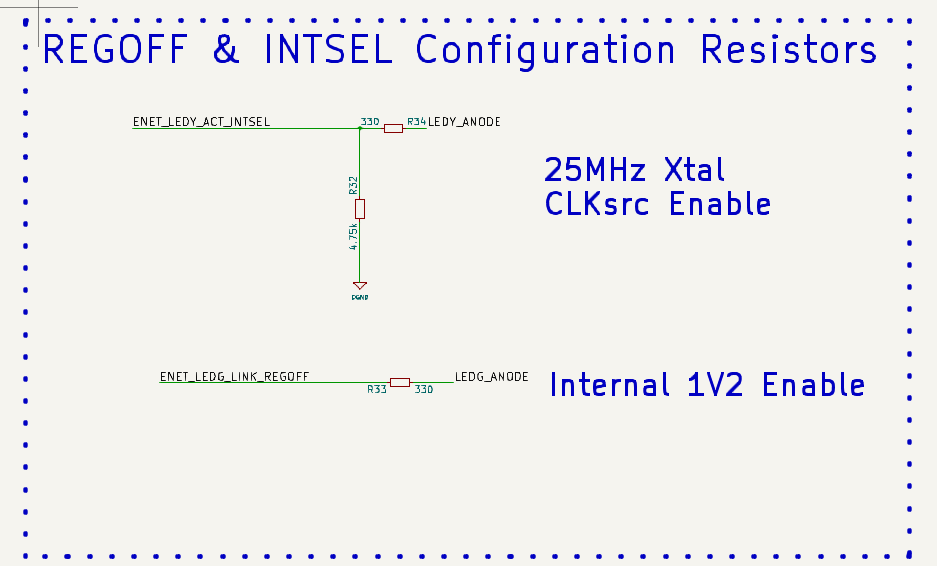
※ RJ45に接続されている2つのLEDのカソードは両方ともGNDへ
ソフトウェアの留意点
RASC(FSP)を使ってRA8E1と接続設定します。
簡単設定なのですが、DMAと割り込みを使うのでそれなりに注意も必要です。
50MHzリファレンスクロック(REF50CLK)はPHYから供給されるのでDisable
User own PHY
現在使用しているFSP v.5.9.0は下記のPHYターゲット初期化コードが整備されています。
- KSZ8091RNB
- KSZ8041
- DP83620
- ICS1894
残念ながらLAN8720Aはリストにありません
- User own PHY
を選びます。初期化コードは用意されません。
もちろんLAN8720Aは無くても動きますが予期せぬリセットなどで必要になるかもしれないので、用意しておいた方が無難です。
初期化APIを自前で用意したら下記項目に関数名を記述しておきます。
Port Custom InitfunctionPort Custom Link Partner Abirity Get Function
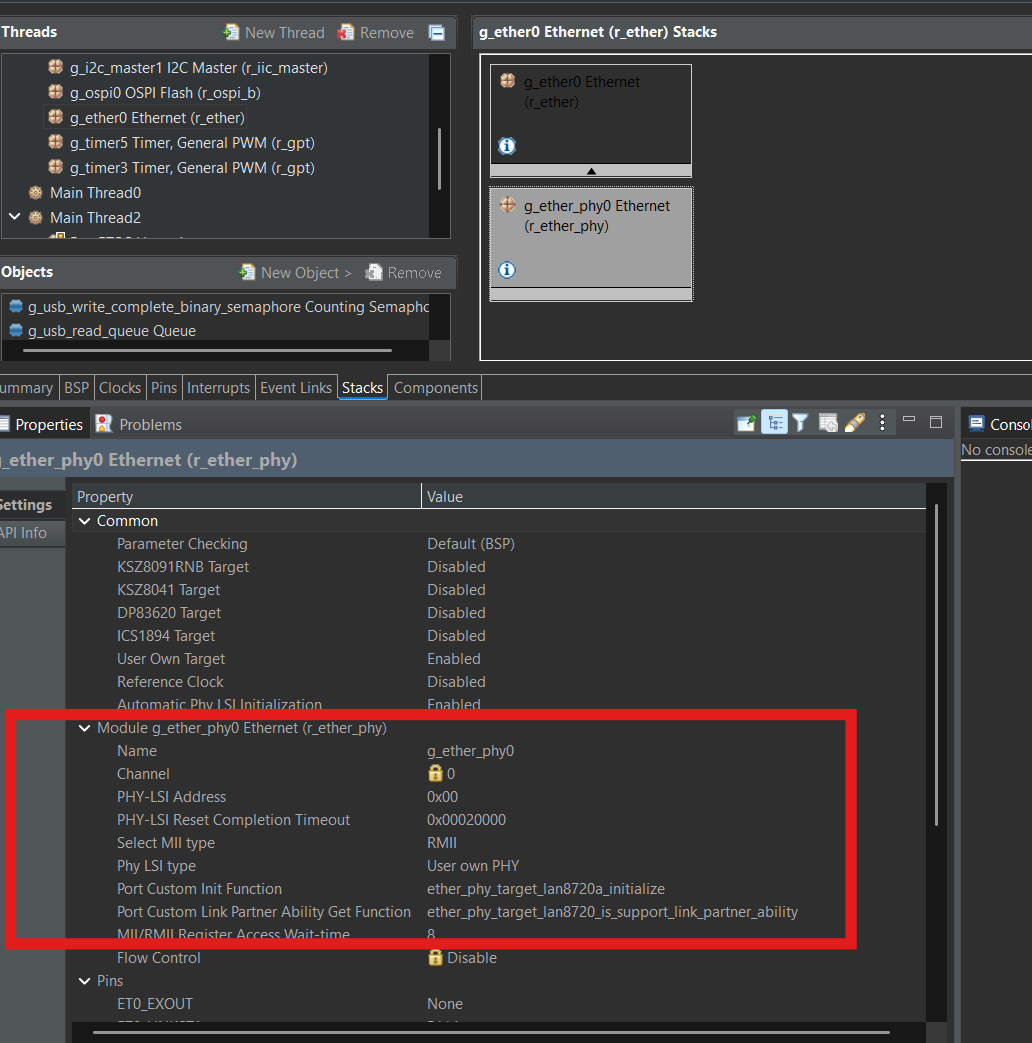
これらの関数の詳細は下記です。
初期化コードether_phy_target_lan8720a_initialize()
初期化コードは無くても動きますが、一応割り込みレジスタとBasic Statusレジスタを空読みします。
割り込みフラグや不確定要因で1になってしまっている予期せぬフラグをクリアするためです(Clear on read)
リンクアビリティether_phy_target_lan8720_is_support_link_partner_ability()
リンクアビリティとは10M/100M/(1G)等通信速度と半/全二重通信の切り替え可能性のようです。
他のRMII-PHYのコード見てもオートネゴシエーション対応デバイスは何もせずにtrueを返しているのでそれに倣います。MODE[2:0] = b'111に設定しているので問題は無いでしょう。知らんけど。
#define ETHER_PHY_REG_BASIC_CONTROL (0) #define ETHER_PHY_REG_BASIC_STATUS (1) #define ETHER_PHY_REG_PHY_ID_1 (2) #define ETHER_PHY_REG_PHY_ID_2 (3) #define ETHER_PHY_REG_INTERRUPT_FLAG (29) #define ETHER_PHY_REG_INTERRUPT_MASK (30) // .... void ether_phy_target_lan8720a_initialize(ether_phy_instance_ctrl_t *p_instance_ctrl) { uint32_t reg = 0x00; R_ETHER_PHY_Read(p_instance_ctrl, ETHER_PHY_REG_BASIC_STATUS, ®); // read basic status reg R_ETHER_PHY_Read(p_instance_ctrl, ETHER_PHY_REG_INTERRUPT_FLAG, ®); // clear interrupt } /* End of function ether_phy_targets_initialize() */ bool ether_phy_target_lan8720_is_support_link_partner_ability(ether_phy_instance_ctrl_t *p_instance_ctrl, uint32_t line_speed_duplex) { FSP_PARAMETER_NOT_USED(p_instance_ctrl); FSP_PARAMETER_NOT_USED(line_speed_duplex); /* This PHY-LSI supports half and full duplex mode. */ return true; } /* End of function ether_phy_targets_is_support_link_partner_ability() */
配線MDIO/MDCが接続されているか確認のため、ユーザーコード側で下記を入れてもいいと思います。
LAN8720Aの場合PHY_ID1レジスタ(0x02)をリードすると必ず0x07(Microchip社のOUI:Orgenization Unique Identifier)が読めます。
uint32_t reg = 0;
R_ETHER_PHY_Read(&g_ether_phy0_ctrl, 0x02, ®);
if(reg == 0x07) // PHY_ID1=7 : Microchip
return true;
else
return false;
もし、0xFF,0x00など異なる値が読めた場合、MDIO/MDC/REF50CLKのいずれかに問題があります。
多くの場合、配線ミスか、FSP設定r_ether_phy->Reference ClockがEnabledになっているのが原因です。Disabledにして再度確認。
逆に言うとここで正しい値が読めれば目の前はゴールです。あとすこし。
イーサーネットフレームを送信・受信する
参考になるのは公式のサンプル
renesas.github.io
の下の方にサンプルがあります。
※ソースコードのコメントを見る限り、このサンプルの記法はちょっと古いらしく、直す必要があります。
少し調査をしてソースコードをなおします。
割り込み
本格的に使うには割り込みはほぼ必須でしょう。
FSPのPHY interruptの項目を見るとEESR,EECRとあります。この項目をクリックしさらに詳細を見ると難解な何らかの略称とそれを有効化するチェックマークが出現します。意味不明なのでこの項目の詳細を調べるためデータシートを見ます。
RA8E1グループユーザーズマニュアル ハードウェア編の28.2.6 EESR:ETHERC/EDMACステータスレジスタの項目です。
https://www.renesas.com/ja/document/mah/ra8e1-group-users-manual-hardware?r=25566640
割り込みはEDMACによりイーサーネットフレームの送信(TC)と受信が完了(FR)したときに発生させたいのでEESRのTCおよびFRにチェックを入れておきます。
改修したソースコード
MACアドレスはAA:BB:CC:DD:EE:FFにしています。
#define ETHER_EXAMPLE_MAXIMUM_ETHERNET_FRAME_SIZE (1514) #define ETHER_EXAMPLE_TRANSMIT_ETHERNET_FRAME_SIZE (1514) #define ETHER_EXAMPLE_SOURCE_MAC_ADDRESS 0xAA, 0xBB, 0xCC, 0xDD, 0xEE, 0xFF #define ETHER_EXAMPLE_DESTINATION_MAC_ADDRESS 0xff, 0xff, 0xff, 0xff, 0xff, 0xff #define ETHER_EXAMPLE_FRAME_TYPE 0x00, 0x2E #define ETHER_EXAMPLE_PAYLOAD 'I', '\'', 'm', ' ', 'R', 'A', '8', 'E', '1', '.', \ ' ', 'H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', \ 'l', 'd', '!', '!', ' ', 'H', 'E', 'L', 'L', 'O', \ ' ', 'W', 'O', 'R', 'L', 'D', '!', ' ', 'R', 'e', \ 'n', 'e', 's', 'a', 's' #define ETHER_EXAMPLE_FLAG_ON (1U) #define ETHER_EXAMPLE_FLAG_OFF (0U) #define ETHER_EXAMPLE_ALIGNMENT_32_BYTE (32) static volatile uint32_t g_example_receive_complete = 0; static volatile uint32_t g_example_transfer_complete = 0; static volatile uint32_t g_example_link_on = 0; #define PHY_BCR_RESET (1 << 15) #define PHY_BCR_AUTONEGO_EN (1 << 12) #define PHY_BCR_RESTART_AUTONEGO (1 << 9) __attribute__((aligned(32))) uint8_t gp_send_data_internal[ETHER_EXAMPLE_TRANSMIT_ETHERNET_FRAME_SIZE] = { ETHER_EXAMPLE_DESTINATION_MAC_ADDRESS, /* Destination MAC address */ ETHER_EXAMPLE_SOURCE_MAC_ADDRESS, /* Source MAC address */ ETHER_EXAMPLE_FRAME_TYPE, /* Type field */ ETHER_EXAMPLE_PAYLOAD /* Payload value (46byte) */ // after bytes, filled with zeros }; void ether_example_callback(ether_callback_args_t *p_args) { switch (p_args->event) { case ETHER_EVENT_TX_COMPLETE: // xprintf("[ISR] TX COMPLETE.\n"); g_example_transfer_complete = 1; break; case ETHER_EVENT_RX_COMPLETE: // xprintf("[ISR] RX COMPLETE.\n"); g_example_receive_complete = 1; break; case ETHER_EVENT_LINK_ON: // xprintf("[ISR] LINK ON.\n"); g_example_link_on = 1; break; case ETHER_EVENT_LINK_OFF: // xprintf("[ISR] LINK OFF.\n"); g_example_link_on = 0; break; default: xprintf("[ISR] Event: %d\n", p_args->event); break; } } /* Main Thread1 entry function */ /* pvParameters contains TaskHandle_t */ void main_thread1_entry(void *pvParameters) { FSP_PARAMETER_NOT_USED(pvParameters); // START:LAN8720A Reset R_BSP_PinAccessEnable(); R_BSP_PinWrite(LAN8720_nRST, BSP_IO_LEVEL_LOW); // Reset LAN8720 xprintf("GPIO = L\n"); vTaskDelay(pdMS_TO_TICKS(300)); R_BSP_PinWrite(LAN8720_nRST, BSP_IO_LEVEL_HIGH); // Start LAN8720 xprintf("GPIO = H\n"); vTaskDelay(pdMS_TO_TICKS(300)); // END:LAN8720A Reset fsp_err_t err = FSP_SUCCESS; err = R_ETHER_Open(&g_ether0_ctrl, &g_ether0_cfg); assert(FSP_SUCCESS == err); xprintf("[ETH] OPEN.\n"); // Check Link ON g_example_link_on = 0; do { err = R_ETHER_LinkProcess(&g_ether0_ctrl); if (err == FSP_SUCCESS || g_example_link_on == 1) { g_example_link_on = 1; break; } } while (g_example_link_on != 1); xprintf("LINK ON\n"); g_example_transfer_complete = 0; /* Set user buffer to TX descriptor and enable transmission. */ err = R_ETHER_Write(&g_ether0_ctrl, (void *)gp_send_data_internal, sizeof(gp_send_data_internal)); if (FSP_SUCCESS == err) { /* Wait for the transmission to complete. */ /* Data array should not change in zero copy mode until transfer complete. */ while (ETHER_EXAMPLE_FLAG_ON != g_example_transfer_complete) { ; } } xprintf("[ETH]Write OK!\n"); /* Get receive buffer from RX descriptor. */ static uint8_t *p_read_buffer_nocopy; uint32_t read_data_size = 0; g_example_receive_complete = 0; err = R_ETHER_Read(&g_ether0_ctrl, (void *)&p_read_buffer_nocopy, &read_data_size); xprintf("[ETH] RCV result:%d\n", err); assert(FSP_SUCCESS == err); /* Process received data here */ if (FSP_SUCCESS == err) { /* Wait for the transmission to complete. */ /* Data array should not change in zero copy mode until transfer complete. */ while (ETHER_EXAMPLE_FLAG_ON != g_example_receive_complete) { ; } } vTaskDelay(pdMS_TO_TICKS(1)); xprintf("[ETH]RCV OK!\n"); /* Release receive buffer to RX descriptor. */ err = R_ETHER_BufferRelease(&g_ether0_ctrl); assert(FSP_SUCCESS == err); // /* Disable transmission and receive function and close the ether instance. */ R_ETHER_Close(&g_ether0_ctrl); xprintf("[ETH]Close.\n"); while (1) { vTaskDelay(pdMS_TO_TICKS(1000)); } }
Wiresharkで確認
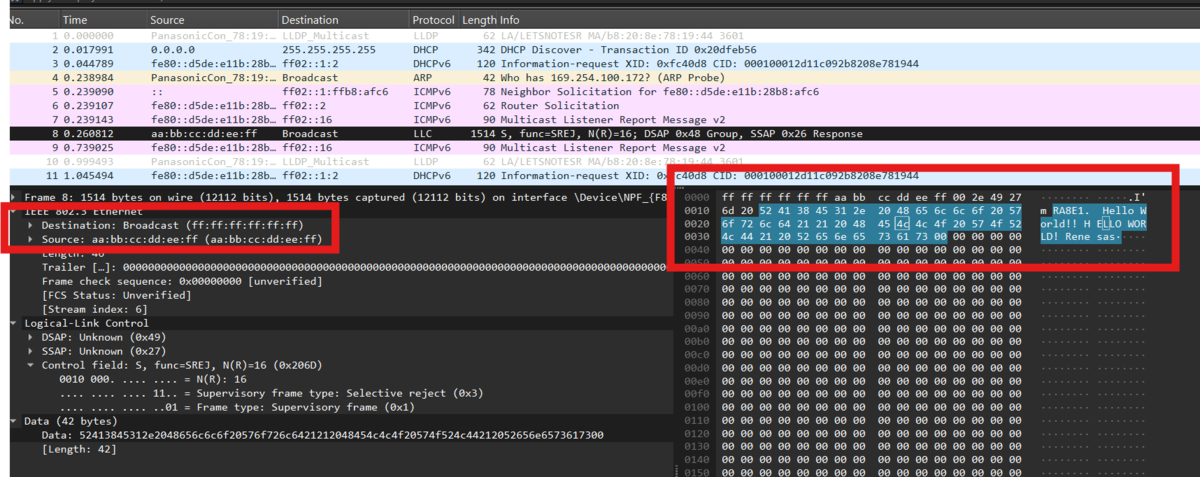
*1:なおソフトウェアでハードウェア初期設定を書き換えることは可能です。詳しくはLAN8720AデータシートのBASIC CONTROL REGISTERの項目をご覧ください